Mental Model
Learn how Orca orchestrates timeseries analytics using a modular architecture of windows, processors, and algorithms. Understand the core components, execution flow, and how Orca enables scalable, language-agnostic data processing.
To effectively use Orca, it helps to develop a clear mental model of how its core concepts - windows, processors, and algorithms - interact. Below is a conceptual breakdown of how these components fit together and how Orca orchestrates them at scale.
What is a Processor?
A Processor is a containerised collections of algorithms, defined as parts of a DAG. It can be written in any language (e.g., Python, TypeScript, via one of our SDKs), and it contains one or more algorithms that operate on incoming windows of data. Each processor declares:
- The algorithms it contains
- Dependencies between algorithms, if any
Processors are registered once during deployment, and can then be reused as part of different analytic workflows.
Example: Processor A (written in Python)
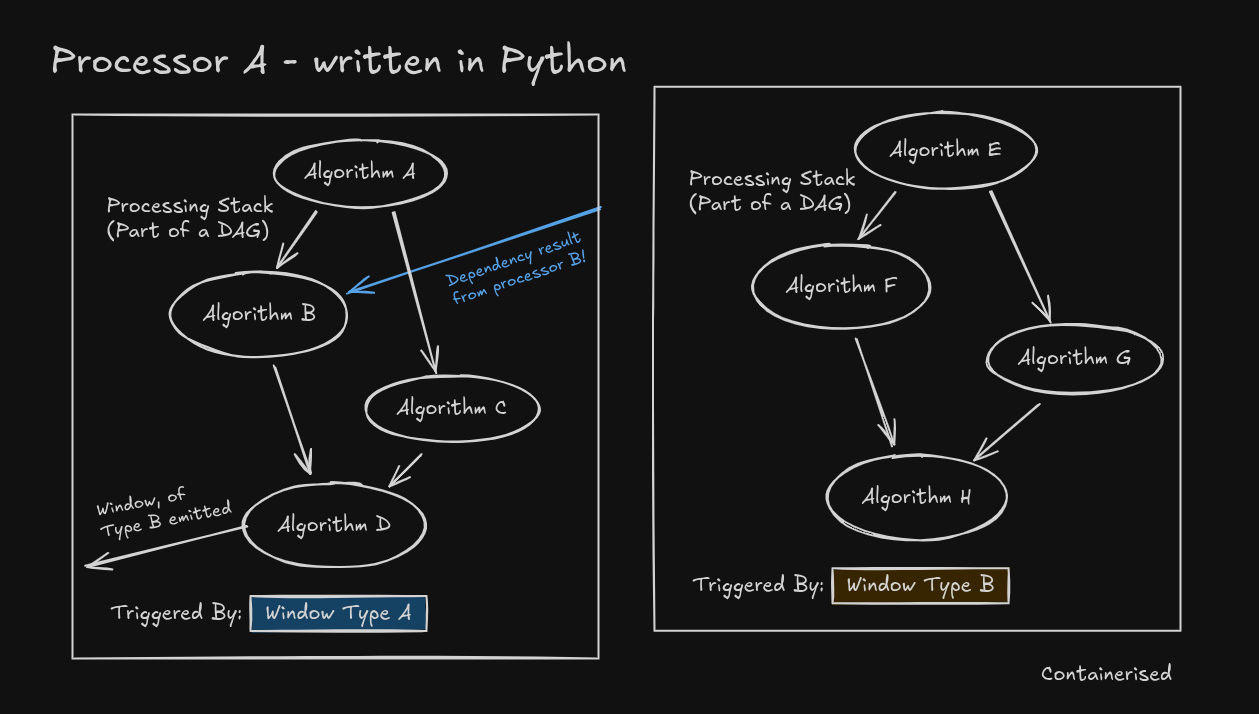
This processor includes multiple algorithms that are chained together - some in parallel, others with dependencies.
There are two DAG parts, triggered by different windows; Window Type A and Window Type B. Each algorithm
in each DAG part produces results specific to the scope of the triggering window.
Example: Processor B (written in TypeScript)
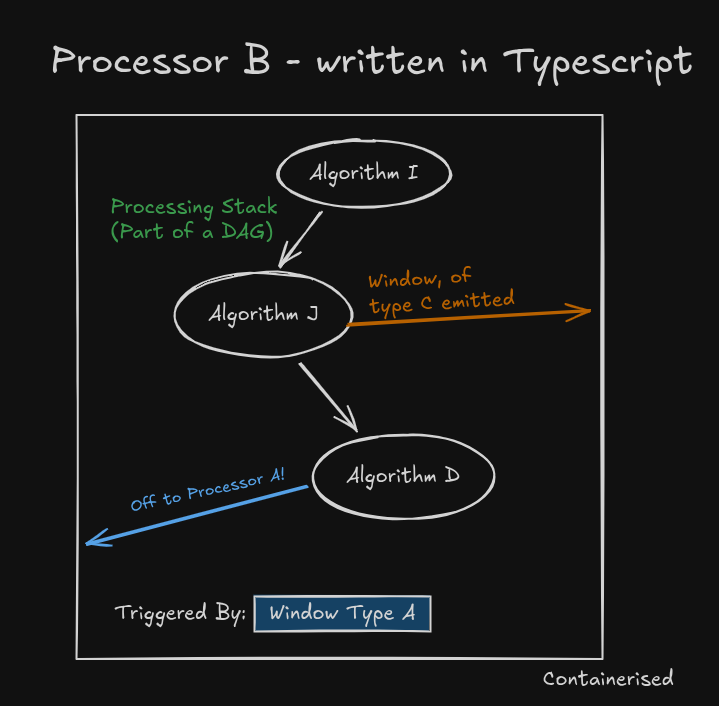
Another processor, this one implemented in TypeScript, also implements a DAG part that is triggered by Window Type A and produces its own set of outputs. It forms part of the same DAG as Processor A. But with the orchestrator as a
seperate service, language choice is irrelevant to how Orca coordinates execution.
Orca Core
At the heart of the system is the Orchestrator - a service responsible for triggering windows, routing data, and managing execution across processors.
Once, during deployment, processors register with the core service, notifying of what algorithms and dependencies each processor has. At this point there is a check on the condition of the DAG to ensure that all will run smoothly in production.
The lifecycle looks something like this:
- A window is emitted (e.g., based on a CRON schedule, event signal, or upstream algorithm).
- The Orchestrator sends a processor request to any matching processor that is registered for that window type.
- The Processor runs the algorithms against that window and sends the result(s) back to the orchestrator.
- The process is repeated, with more requests being sent to processors untill the complete DAG for that window is completed.
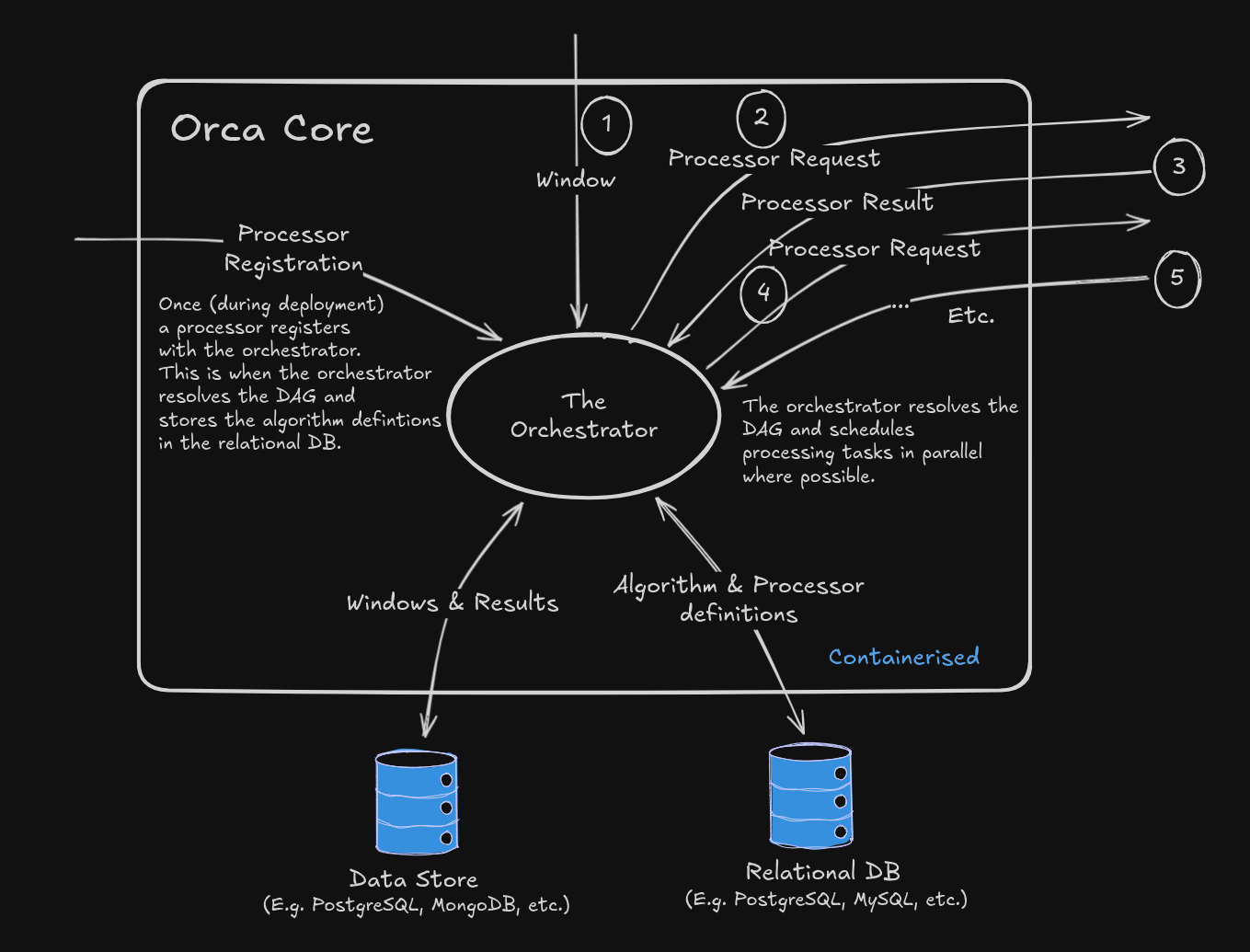
Key Concepts:
- Window: A region of time that defines when something of interest is happening, specific to an object or service
- Algorithm: A unit of computation. Algorithms live inside processors and accept windows, and other algorithm results, as arguments
- Processor: A containerised service that registers with Orca and contains the logic to process one or more algorithms, as parts of a larger DAG
- Orchestrator: The runtime engine that that matches windows to processors, triggers computation, and collects results in an efficient and parallelised manner.
This architecture decouples orchestration logic from data processing, enabling modularity, parallelism, and scale - all while keeping the user in full control of how and when analysis runs.
Data Stores
There are two types of data store required for Orca:
- Relational Store
- Stream Store
The relational store is used to store semi-static information regarding the relationship between windows, processors and algorithms.
The stream store is used to store the algorithm results, windows that are emitted to orca-core execution status.
These two functions can be seperated across database type (e.g. MySQL and MongoDB respectively) or contained within the same database.
Get Started
By thinking in terms of windows, processors, and algorithms, you can model complex analytical pipelines that are robust, flexible, and production-ready.
Check out the Quickstart Guide to understand how you can get going with orca locally.